Tuning Fledge¶
Many factors will impact the performance of a Fledge system
The CPU, memory and storage performance of the underlying hardware
The communication channel performance to the sensors
The communications to the north systems
The choice of storage system
The external demands via the public REST API
Many of these are outside of the control of Fledge itself, however it is possible to tune the way Fledge will use certain resources to achieve better performance within the constraints of a deployment environment.
South Service Advanced Configuration¶
The south services within Fledge each have a set of advanced configuration options defined for them. These are accessed by editing the configuration of the south service itself. A screen with a set of tabbed panes will appear, select the tab labeled Advanced Configuration to view and edit the advanced configuration options.
|
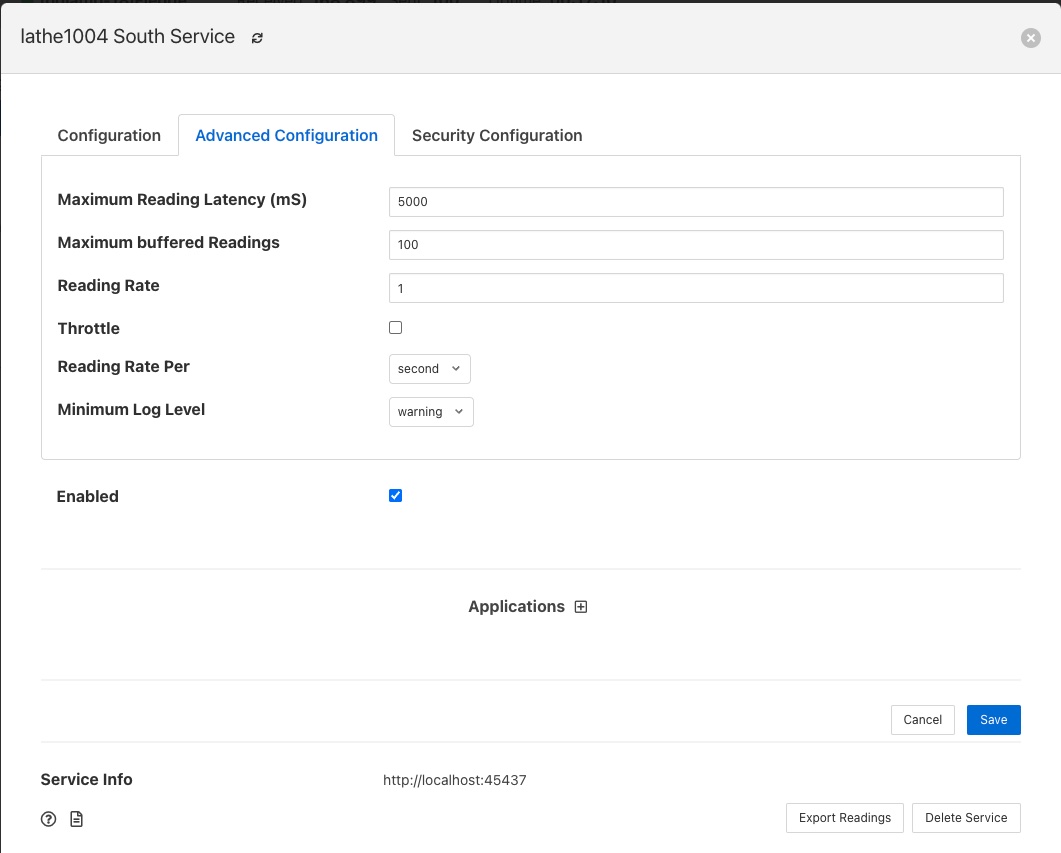
Maximum Reading Latency (mS) - This is the maximum period of time for which a south service will buffer a reading before sending it onward to the storage layer. The value is expressed in milliseconds and it effectively defines the maximum time you can expect to wait before being able to view the data ingested by this south service.
Maximum buffered Readings - This is the maximum number of readings the south service will buffer before attempting to send those readings onward to the storage service. This and the setting above work together to define the buffering strategy of the south service.
Reading Rate - The rate at which polling occurs for this south service. This parameter only has effect if your south plugin is polled, asynchronous south services do not use this parameter. The units are defined by the setting of the Reading Rate Per item.
Throttle - If enabled this allows the reading rate to be throttled by the south service. The service will attempt to poll at the rate defined by Reading Rate, however if this is not possible, because the readings are being forwarded out of the south service at a lower rate, the reading rate will be reduced to prevent the buffering in the south service from becoming overrun.
Reading Rate Per - This defines the units to be used in the Reading Rate value. It allows the selection of per second, minute or hour.
Minimum Log Level - This configuration option can be used to set the logs that will be seen for this service. It defines the level of logging that is send to the syslog and may be set to error, warning, info or debug. Logs of the level selected and higher will be sent to the syslog. You may access the contents of these logs by selecting the log icon in the bottom left of this screen.
Tuning Buffer Usage¶
The tuning of the south service allows the way the buffering is used within the south service to be controlled. Setting the latency value low results in frequent calls to send data to the storage service and therefore means data is more quickly available. However sending small quantities of data in each call the the storage system does not result in the most optimal use of the communications or of the storage engine itself. Setting a higher latency value results in more data being sent per transaction with the storage system and a more efficient system. The cost of this is the requirement for more in-memory storage within the south service.
Setting the Maximum buffers Readings value allows the user to place a cap on the amount of memory used to buffer within the south service, since when this value is reach, regardless of the age of the data and the setting of the latency parameter, the data will be sent to the storage service. Setting this to a smaller value allows tighter control on the memory footprint at the cost of less efficient use of the communication and storage service.
Tuning between performance, latency and memory usage is always a balancing act, there are situations where the performance requirements mean that a high latency will need to be incurred in order to make the most efficient use of the communications between the micro services and the transnational performance of the storage engine. Likewise the memory resources available for buffering may restrict the performance obtainable.
North Advanced Configuration¶
In a similar way to the south services, north services and tasks also have advanced configuration that can be used to tune the operation of the north side of Fledge. The north advanced configuration is accessed in much the same way as the south, select the North page and open the particular north service or task. A tabbed screen will be shown which contains an Advanced Configuration tab.
|
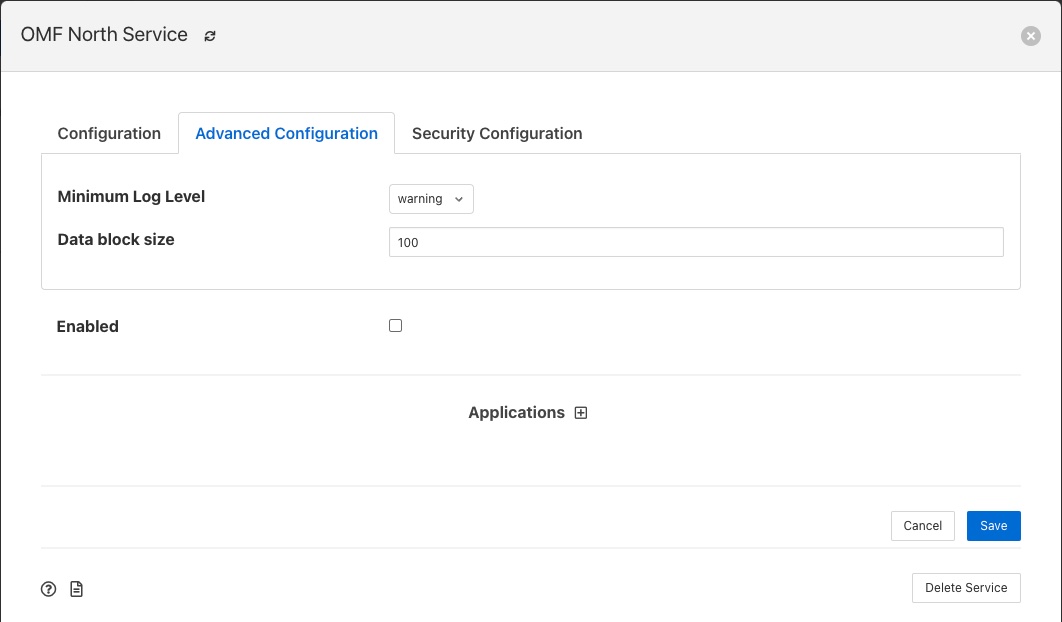
Minimum Log Level - This configuration option can be used to set the logs that will be seen for this service or task. It defines the level of logging that is send to the syslog and may be set to error, warning, info or debug. Logs of the level selected and higher will be sent to the syslog. You may access the contents of these logs by selecting the log icon in the bottom left of this screen.
Data block size - This defines the number of readings that will be sent to the north plugin for each call to the plugin_send entry point. This allows the performance of the north data pipeline to be adjusted, with larger blocks sizes increasing the performance, by reducing overhead, but at the cost of requiring more memory in the north service or task to buffer the data as it flows through the pipeline. Setting this value too high may cause issues for certain of the north plugins that have limitations on the number of messages they can handle within a single block.
Health Monitoring¶
The Fledge core monitors the health of other services within Fledge, this is done with the Service Monitor within Fledge and can be configured via the Configuration menu item in the Fledge user interface. In the configuration page select the Advanced options and then the Service Monitor section.
|
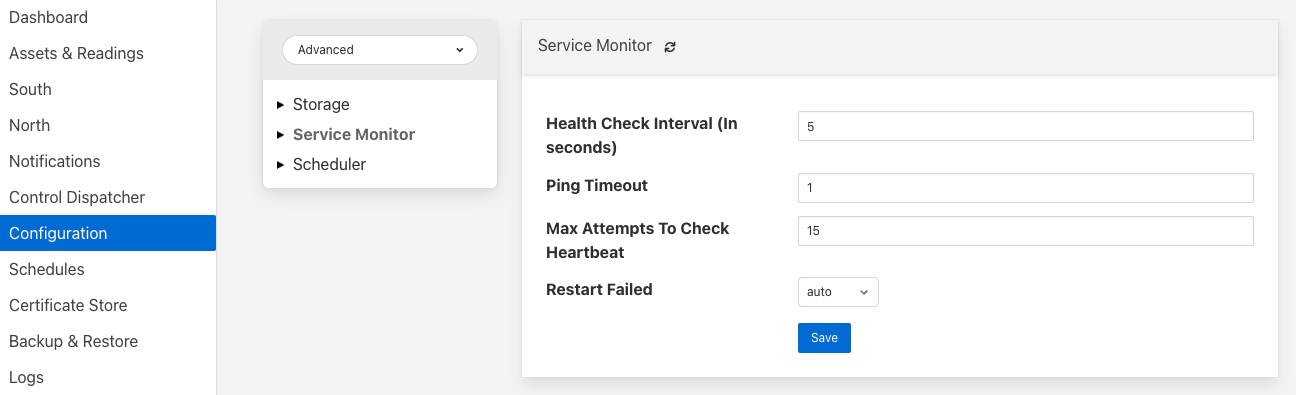
Health Check Interval - This setting determines how often Fledge will send a health check request to each of the microservices within the Fledge instance. The value is expressed in seconds. Making this value small will decrease the amount of time it will take to detect a failure, but will increase the load on the system for performing health checks. Making this too frequent is likely to increase the occurrence of false failure detection.
Ping Timeout - Amount of time to wait, in seconds, before declaring that a health check request has failed. Failure for a health check response to be seen within this time will make a service as unresponsive. Small values can result in busy services becoming suspect erroneously.
Max Attempts To Check Heartbeat - This is the number of heartbeat requests that must fail before the core determines that the service has failed and attempts any restorative action. Reducing this value will cause the service to be declared as failed sooner and hence recovery can be performed sooner. If this value is too small then it can result in multiple instances of a service running or frequent restarts occurring. Making this too long results in loss of data.
Restart Failed - Determine what action should be taken when a service is detected as failed. Two options are available, Manual, in which case not automatic action will be taken, or Auto, in which case the service will be automatically restarted.
Scheduler¶
The Fledge core contains a scheduler that is used for running periodic tasks, this scheduler has a couple of tuning parameters. To access these parameters from the Fledge User Interface, in the configuration page select the Advanced options and then the Scheduler section.
|

Max Running Tasks - Specifies the maximum number of tasks that can be running at any one time. This parameter is designed to stop runaway tasks adversely impacting the performance of the system. When this number is reached no new tasks will be created until one or more of the currently running tasks terminated. Set this too low and you will not be able to run all the task you require in parallel. Set it too high and the system is more at risk from runaway tasks.
Max Age of Task - Specifies, in days, how long a task can run for. Tasks that run longer than this will be killed by the system.
Note
Individual tasks have a setting that they may use to stop multiple instances of the same task running in parallel. This also helps protect the system from runaway tasks.
Storage¶
The storage layer is perhaps one of the areas that most impacts the overall performance of the Fledge instance as it is the end point for the data pipelines; the location at which all ingest pipelines in the south terminate and the point of origin for all north pipelines to external systems.
The storage system in Fledge serves two purposes
The storage of configuration and persistent state of Fledge itself
The buffering of reading data as it traverses the Fledge instance
The physical storage is managed by plugins that are loaded dynamically into the storage service in the same way as with other services in Fledge. In the case of the storage service it may have either one or two plugins loaded. If a single plugin is loaded this will be used for the storage of both configuration and readings; if two plugins are loaded then one will be used for storing the configuration and the other for storing the readings. Not all plugins support both classes of data.
Choosing A Storage Plugin¶
Fledge comes with a number of storage plugins that may be used, each one has it benefits and limitations, below is an overview of each of the plugins that are currently included with Fledge.
- sqlite
The default storage plugin that is used. It is implemented using the SQLite database and is capable of storing both configuration and reading data. It is optimized to allow parallelism when multiple assets are being ingested into the Fledge instance. It does however have limitations on the number of different assets that can be ingested within an instance. The precise limit is dependent upon a number of other factors, but is of the order of 900 unique asset names per instance. This is a good general purpose storage plugin and can manage reasonably high rates of data reading.
- sqlitelb
This is another SQLite based plugin able to store both readings and configuration data. It is designed for lower bandwidth data, hence the name suffix lb. It does not have the same parallelism optimization as the default sqlite plugin, and is therefore less good when high rate data spread across multiple assets is being ingested. However it does perform well when ingesting high rates of a single asset or low rates of a very large number of assets. It does not have any limitations on the number of different assets that can be stored within the Fledge instance.
- sqlitememory
This is a SQLite based plugin that uses in memory tables and can only be used to store reading data, it must be used in conjunction with another plugin that will be used to store the configuration. Reading data is stored in tables in memory and thus very high bandwidth data can be supported. If Fledge is shutdown however the data stored in these tables will be lost.
- postgres
This plugin is implemented using the PostgreSQL database and supports the storage of both configuration and reading data. It uses the standard Postgres storage engine and benefits from the additional features of Postgres for security and replication. It is capable of high levels of concurrency however has slightly less overall performance than the sqlite plugins. Postgres also does not work well with certain types of storage media, such as SD cards as it has a higher ware rate on the media.
In most cases the default sqlite storage plugin is perfectly acceptable, however if very high data rates, or huge volumes of data (i.e. large images at a reasonably high rate) are ingested this plugin can start to exhibit issues. This usually exhibits itself by large queues building in the south service or in extreme cases by transaction failure messages in the log for the storage service. If this happens then the recommended course of action is to either switch to a plugin that stores data in memory rather than on external storage, sqlitememory, or investigate the media where the data is stored. Low performance storage will adversely impact the sqlite plugin.
The sqlite plugin may also prove less than optimal if you are ingested many hundreds of different assets in the same Fledge instance. The sqlite plugin has been optimized to allow concurrent south services to write to the storage in parallel. This is done by the use of multiple databases to improve the concurrency, however there is a limit, imposed by the number of open databases that can be supported. If this limit is exceeded it is recommend to switch to the sqlitelb plugin. There are configuration options regarding how these databases are used that can change the point at which it becomes necessary to switch to the other plugin.
Configuring Storage Plugins¶
The storage plugins to use can be selected in the Advanced section of the Configuration page. Select the Storage category from the category tree display and the following will be displayed.
|
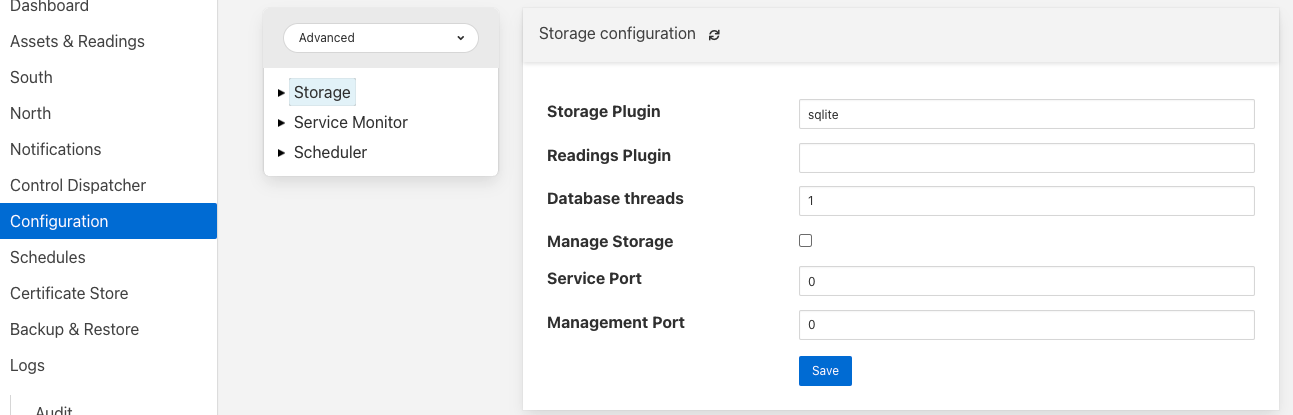
Storage Plugin: The name of the storage plugin to use. This will be used to store the configuration data and must be one of the supported storage plugins.
Note
This can not be the sqlitememory plugin as that plugin does not support the storage of configuration.
Reading Plugin: The name of the storage plugin that will be used to store the readings data. If left blank then the Storage Plugin above will be used to store both configuration and readings.
Database threads: Increase the number of threads used within the storage service to manage the database activity. This is not the number of threads that can be used to read or write the database and increasing this will not improve the throughput of the data.
Manage Storage: This is used when an external storage application, such as the Postgres database is used that requires separate initialization. If this external process is not run by default setting this to true will cause Fledge to start the storage process. Normally this is not required as Postgres should be run as a system service and SQLite does not require it.
Service Port: Normally the storage service will dynamically create a service port that will be used by the storage service. Setting this to a value other than 0 will cause a fixed port to be used. This can be useful when developing a new storage plugin or to allow access to a non-fledge application to the storage layer. This should only be changed with extreme caution.
Management Port: Normally the storage service will dynamically create a management port that will be used by the storage service. Setting this to a value other than 0 will cause a fixed port to be used. This can be useful when developing a new storage plugin.
Changing will be saved once the save button is pressed. Fledge uses a mechanism whereby this data is not only saved in the configuration database, but also cached to a file called storage.json in the etc directory of the data directory. This is required such that Fledge can find the configuration database during the boot process. If the configuration becomes corrupt for some reason simply removing this file and restarting Fledge will cause the default configuration to be restored. The location of the Fledge data directory will depend upon how you installed Fledge and the environment variables used to run Fledge.
Installation from a package will usually put the data directory in /usr/local/fledge/data. However this can be overridden by setting the $FLEDGE_DATA environment variable to point at a different location.
When running a copy of Fledge built from source the data directory can be found in ${FLEDGE_ROOT}/data. Again this may be overridden by setting the $FLEDGE_DATA environment variable.
Note
When changing the storage service a reboot of the Fledge instance is required before the new storage plugins will be used. Also, data is not migrated from one plugin to another and hence if there is unsent data within the database this will be lost when changing the storage plugin. The sqlite and sqlitelb plugin however share the same configuration data tables and hence configuration will be preserved when changing between these databases but reading data will not.
sqlite Plugin Configuration¶
The storage plugin configuration can be found in the Advanced section of the Configuration page. Select the Storage category from the category tree display and the plugin name from beneath that category. In the case of the sqlite storage plugin the following will be displayed.
|
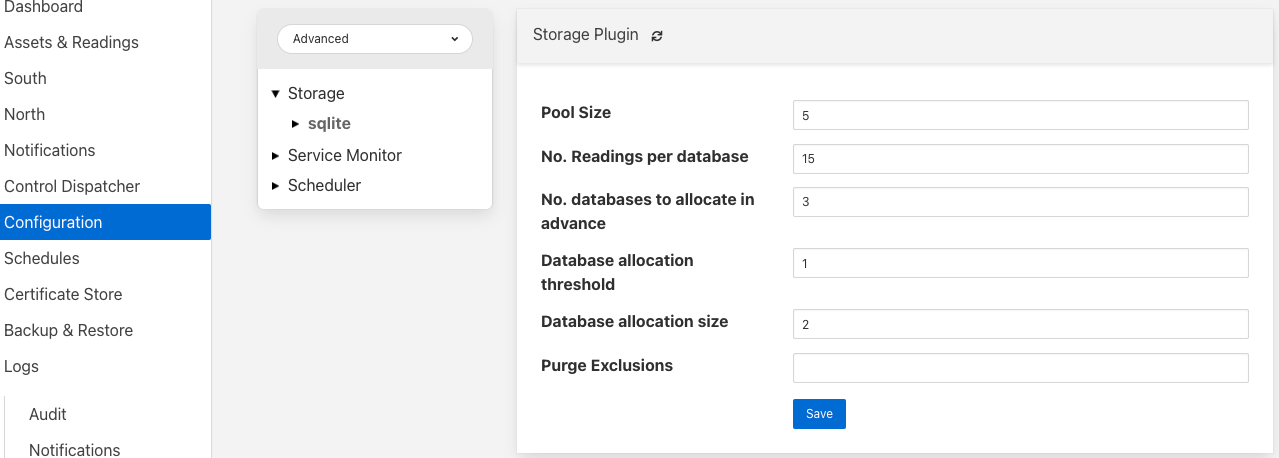
Pool Size: The storage service uses a connection pool to communicate with the underlying database, it is this pool size that determines how many parallel operations can be invoked on the database.
This pool size is only the initial size, the storage service will grow the pool if required, however setting a realistic initial pool size will improve the ramp up performance of Fledge.
Note
Although the pool size denotes the number of parallel operations that can take place, database locking considerations may reduce the number of actual operations in progress at any point in time.
No. Readings per database: The sqlite plugin support multiple readings databases, with the name of the asset used to determine which database to store the readings in. This improves the level of parallelism by reducing the lock contention when data is being written. Setting this value to 1 will cause only a single asset name to be stored within a single readings database, resulting in no contention between assets. However there is a limit on the number of databases, therefore setting this to 1 will limit the number of different assets that can be ingested into the instance.
No. databases to allocate in advance: This controls how many reading databases Fledge should initially created. Creating databases is a slow process and thus is best achieved before data starts to flow through Fledge. Setting this too high will cause Fledge to allocate a large number of databases than required and waste open database connections. Ideally set this to the number of different assets you expect to ingest divided by the number of readings per database configuration above. This should give you sufficient databases to store the data you require.
Database allocation threshold: The allocation of a new database is a slow process, therefore rather than wait until there are no available databases before allocating new ones, it is possible to pre-allocate database as the number of free databases becomes low. This value allows you to set the point at which to allocation more databases. As soon as the number of free databases declines to this value the plugin will allocate more databases.
Database allocation size: The number of new databases to create whenever an allocation occurs. This effectively denotes the size of the free pool of databases that should be created.
Purge Exclusion: This is not a performance settings, but allows a number of assets to be exempted from the purge process. This value is a comma separated list of asset names that will be excluded from the purge operation.
sqlitelb Configuration¶
The storage plugin configuration can be found in the Advanced section of the Configuration page. Select the Storage category from the category tree display and the plugin name from beneath that category. In the case of the sqlitelb storage plugin the following will be displayed.
|

Note
The sqlite configuration is still present and selectable since this instance has run that storage plugin in the past and the configuration is preserved when switching between sqlite and sqlitelb plugins.
Pool Size: The storage service uses a connection pool to communicate with the underlying database, it is this pool size that determines how many parallel operations can be invoked on the database.
This pool size is only the initial size, the storage service will grow the pool if required, however setting a realistic initial pool size will improve the ramp up performance of Fledge.
Note
Although the pool size denotes the number of parallel operations that can take place, database locking considerations may reduce the number of actual operations in progress at any point in time.
postgres Configuration¶
The storage plugin configuration can be found in the Advanced section of the Configuration page. Select the Storage category from the category tree display and the plugin name from beneath that category. In the case of the postgres storage plugin the following will be displayed.
|

Pool Size: The storage service uses a connection pool to communicate with the underlying database, it is this pool size that determines how many parallel operations can be invoked on the database.
This pool size is only the initial size, the storage service will grow the pool if required, however setting a realistic initial pool size will improve the ramp up performance of Fledge.
Note
Although the pool size denotes the number of parallel operations that can take place, database locking considerations may reduce the number of actual operations in progress at any point in time.
sqlitememory Configuration¶
The storage plugin configuration can be found in the Advanced section of the Configuration page. Select the Storage category from the category tree display and the plugin name from beneath that category. Since this plugin only supports the storage of readings there will always be at least one other reading plugin displayed. Selecting the sqlitememory storage plugin the following will be displayed.
|

Pool Size: The storage service uses a connection pool to communicate with the underlying database, it is this pool size that determines how many parallel operations can be invoked on the database.
This pool size is only the initial size, the storage service will grow the pool if required, however setting a realistic initial pool size will improve the ramp up performance of Fledge.
Note
Although the pool size denotes the number of parallel operations that can take place, database locking considerations may reduce the number of actual operations in progress at any point in time.